This Document explains the steps of how we read an XML data file using PLSQL and write them to oracle tables.
Create a UTL Directory:
This involves the following steps. Creating a Logical directory and giving the Permissions to access this directory using an URL. Using the XML Dom Parser Procedures to read the Xml file , parse it
and then load it into the respective columns.
1) Create a logical directory
Create or replace directory TEST_LOB_DIR as ‘/data/tst1/attachment’
It creates a directory with Owner SYS.Grant privileges on this directory to Apps.
2) Create a physical directory at the given location ‘/data/tst1/attachment’
Permissions on this directory too.This directory has to be a UTL directory.
3) Edit the conf file at this path
Cd $IAS_ORACLE_HOME/Apache/Apache/conf
==>/apps/applmgr/tst1ora/IAS/Apache/Apache/conf
Edit the file apps.conf
Alias /attachment/ “/data/tst1/attachment/”
<Location /attachment/>
Order allow, deny
Allow from all
</Location>
4) Bounce the Apache.
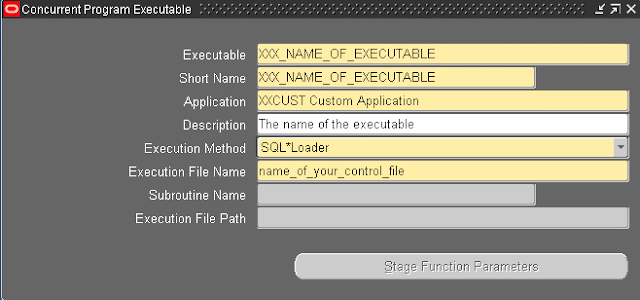
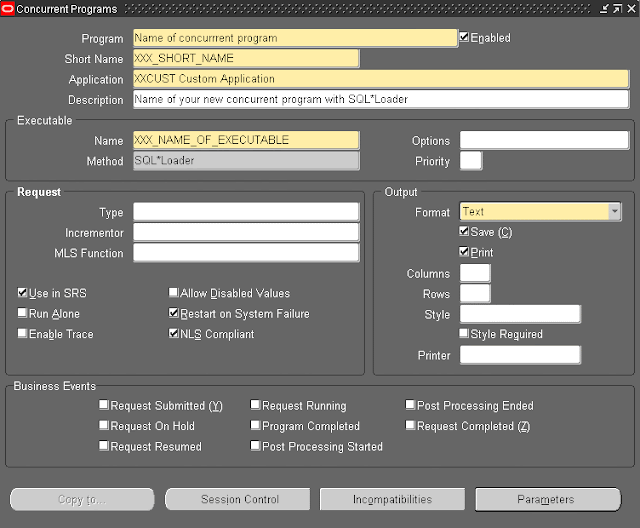
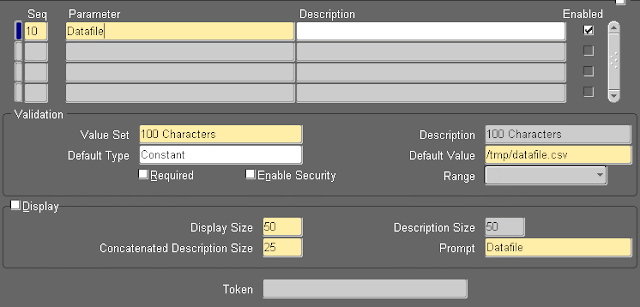
Create a procedure to parse and retrieve the XML data and then insert it into appropriate columns in the database.
Used two PLSQL packages for these –
1. XMLPARSER
2. XMLDOM
1. XMLParser – Procedures
i.)parse(p Parser, url VARCHAR2)
Description – The parse procedure takes two parameters which are the parse object and the url of the
xml file that has to parsed.
ii.) setValidationMode(p Parser, yes BOOLEAN)
Checks whether XML is Valid or not.
iii.) setBaseDir(p Parser, dir VARCHAR2)
Sets the base url or directory path.
iv.) getDocument(p Parser)
Get the Document which has to be parsed.
2. XMLDOM
DOMDocument
DOMELEMENT
DOMNODELIST
DOMNODE
DOMNamedNodeMap
FUNCTIONS –
getNodeName(n DOMNode) RETURN VARCHAR2 – Retrieves the Name of the Node
getNodeValue(n DOMNode) RETURN VARCHAR2 – Retrieves the Value of the Node
getElementsByTagName(doc DOMDocument, tagname IN VARCHAR2)- Retrieves the elements in
the by tag name
getDocumentElement(doc DOMDocument) RETURN DOMElement – Retrieves the root element of
the document
getFirstChild(n DOMNode) RETURN DOMNode – Retrieves the first child of the node
getLength(nl DOMNodeList) RETURN NUMBER- Retrieves the number of items in the list.
Sample XML File
Create a UTL Directory:
This involves the following steps. Creating a Logical directory and giving the Permissions to access this directory using an URL. Using the XML Dom Parser Procedures to read the Xml file , parse it
and then load it into the respective columns.
1) Create a logical directory
Create or replace directory TEST_LOB_DIR as ‘/data/tst1/attachment’
It creates a directory with Owner SYS.Grant privileges on this directory to Apps.
2) Create a physical directory at the given location ‘/data/tst1/attachment’
Permissions on this directory too.This directory has to be a UTL directory.
3) Edit the conf file at this path
Cd $IAS_ORACLE_HOME/Apache/Apache/conf
==>/apps/applmgr/tst1ora/IAS/Apache/Apache/conf
Edit the file apps.conf
Alias /attachment/ “/data/tst1/attachment/”
<Location /attachment/>
Order allow, deny
Allow from all
</Location>
4) Bounce the Apache.
Create a procedure to parse and retrieve the XML data and then insert it into appropriate columns in the database.
Used two PLSQL packages for these –
1. XMLPARSER
2. XMLDOM
1. XMLParser – Procedures
i.)parse(p Parser, url VARCHAR2)
Description – The parse procedure takes two parameters which are the parse object and the url of the
xml file that has to parsed.
ii.) setValidationMode(p Parser, yes BOOLEAN)
Checks whether XML is Valid or not.
iii.) setBaseDir(p Parser, dir VARCHAR2)
Sets the base url or directory path.
iv.) getDocument(p Parser)
Get the Document which has to be parsed.
2. XMLDOM
DOMDocument
DOMELEMENT
DOMNODELIST
DOMNODE
DOMNamedNodeMap
FUNCTIONS –
getNodeName(n DOMNode) RETURN VARCHAR2 – Retrieves the Name of the Node
getNodeValue(n DOMNode) RETURN VARCHAR2 – Retrieves the Value of the Node
getElementsByTagName(doc DOMDocument, tagname IN VARCHAR2)- Retrieves the elements in
the by tag name
getDocumentElement(doc DOMDocument) RETURN DOMElement – Retrieves the root element of
the document
getFirstChild(n DOMNode) RETURN DOMNode – Retrieves the first child of the node
getLength(nl DOMNodeList) RETURN NUMBER- Retrieves the number of items in the list.
Sample XML File
-<vapi_HRMS>
– <record>
<EmpID>O01006923</EmpID>
<vcEmp_Full_Name>Vinod Mudakkayil</vcEmp_Full_Name>
<vcDesignation>VP</vcDesignation>
<chLevel>L8</chLevel>
<chGrade>-</chGrade>
<vcDepartment>HR-Recruitment</vcDepartment>
<vcProgram_Name>HR – Recruitment</vcProgram_Name>
<vcSub_Program_Name>HR-Recruitment</vcSub_Program_Name>
<vcEmail_ID>[email protected]</vcEmail_ID>
<vcCentername>Bangalore</vcCentername>
<intSeniorID>01040101</intSeniorID>
<Hop_Id>101006923</Hop_Id>
<VP_Id>101006923</VP_Id>
<VCEMP_STATUS>CORPORATE</VCEMP_STATUS>
<vcEmp_First_Name>Vinod</vcEmp_First_Name>
<vcEmp_Last_Name>Mudakkayil</vcEmp_Last_Name>
<vcEmp_Gender>Male</vcEmp_Gender>
<vcEmp_DOJ>2005/04/07</vcEmp_DOJ>
<dob>4-Mar-1963</dob>
</record>
– <record>
<EmpID>P01006923</EmpID>
<vcEmp_Full_Name>Vinod Mudakkayil</vcEmp_Full_Name>
<vcDesignation>VP</vcDesignation>
<chLevel>L8</chLevel>
<chGrade>-</chGrade>
<vcDepartment>HR-Recruitment</vcDepartment>
<vcProgram_Name>HR – Recruitment</vcProgram_Name>
<vcSub_Program_Name>HR-Recruitment</vcSub_Program_Name>
<vcEmail_ID>[email protected]</vcEmail_ID>
<vcCentername>Bangalore</vcCentername>
<intSeniorID>01040101</intSeniorID>
<Hop_Id>01006923,101006923,O01006923</Hop_Id>
<VP_Id>O01006923</VP_Id>
<VCEMP_STATUS>CORPORATE</VCEMP_STATUS>
<vcEmp_First_Name>Vinod</vcEmp_First_Name>
<vcEmp_Last_Name>Mudakkayil</vcEmp_Last_Name>
<vcEmp_Gender>Male</vcEmp_Gender>
<vcEmp_DOJ>2005/04/07</vcEmp_DOJ>
<dob>4-Mar-1963</dob>
</record>
</vapi_HRMS>
Sample Code:
— Call the procedure —
PROCEDURE xml_perse (
errbuf OUT VARCHAR2,
retcode OUT NUMBER,
dir VARCHAR2,
inpfile VARCHAR2
)
IS
p xmlparser.parser;
doc xmldom.domdocument;
docelem DBMS_XMLDOM.domelement;
— prints elements in a document
BEGIN
— new parser
p := xmlparser.newparser;
— set some characteristics
xmlparser.setvalidationmode (p, FALSE);
fnd_file.put_line (fnd_file.LOG, ‘ xml_perse Validated’);
–xmlparser.setErrorLog(p, dir || ‘/’ || errfile);
xmlparser.setbasedir (p, dir);
fnd_file.put_line (fnd_file.LOG, ‘ xml_perse set path’);
— parse input file
xmlparser.parse (p, dir || ‘/’ || inpfile);
fnd_file.put_line (fnd_file.LOG, ‘ xml_perse parse’);
— get document
doc := xmlparser.getdocument (p);
fnd_file.put_line (fnd_file.LOG, ‘ xml_perse get document’);
— Print document elements
DBMS_OUTPUT.put (‘The elements are: ‘);
printelements (doc);
COMMIT;
EXCEPTION
WHEN OTHERS
THEN
–SQLERRM
DBMS_OUTPUT.put (SQLERRM);
END xml_perse;
PROCEDURE printelements (doc xmldom.domdocument)
IS
nl1 xmldom.domnodelist;
nl2 xmldom.domnodelist;
nl3 xmldom.domnodelist;
nl4 xmldom.domnodelist;
nl5 xmldom.domnodelist;
len1 NUMBER;
len2 NUMBER;
len3 NUMBER;
len4 NUMBER;
len5 NUMBER;
n1 xmldom.domnode;
n2 xmldom.domnode;
n3 xmldom.domnode;
n4 xmldom.domnode;
nnm xmldom.domnamednodemap;
attrname VARCHAR (1000);
attrval VARCHAR (1000);
v_empid VARCHAR2 (1000);
v_emp_full_name VARCHAR2 (1000);
v_designation VARCHAR2 (1000);
BEGIN
— get all elements
fnd_file.put_line (fnd_file.LOG, ‘get all elements’);
nl1 := xmldom.getelementsbytagname (doc, ‘record’);
nl2 := xmldom.getelementsbytagname (doc, ‘EmpID’);
nl3 := xmldom.getelementsbytagname (doc, ‘vcEmp_Full_Name’);
nl4 := xmldom.getelementsbytagname (doc, ‘vcDesignation’);
fnd_file.put_line (fnd_file.LOG, ‘Length of the Elements’);
— Length of the Elements
len1 := xmldom.getlength (nl1);
len2 := xmldom.getlength (nl2);
len3 := xmldom.getlength (nl3);
len4 := xmldom.getlength (nl4);
— loop through elements
FOR i IN 0 .. len1 – 1
LOOP
v_empid := NULL;
v_emp_full_name := NULL;
v_designation := NULL;
n1 := xmldom.item (nl1, i);
n2 := xmldom.item (nl2, i);
n3 := xmldom.item (nl3, i);
n4 := xmldom.item (nl4, i);
v_empid := xmldom.getnodevalue (n2);
v_emp_full_name := xmldom.getnodevalue (n3);
v_designation := xmldom.getnodevalue (n4);
fnd_file.put_line (fnd_file.LOG, ‘***************************’);
fnd_file.put_line (fnd_file.LOG, v_empid);
fnd_file.put_line (fnd_file.LOG, v_emp_full_name);
fnd_file.put_line (fnd_file.LOG, v_designation);
fnd_file.put_line (fnd_file.LOG, ‘***************************’);
DELETE FROM xx_employee_temp;
–WHERE status = ‘S’;
INSERT INTO xx_employee_temp
(empid, emp_full_name, designation,status, error_description
)
VALUES (v_empid, v_emp_full_name, v_designation,NULL, NULL
);
DBMS_OUTPUT.put_line (‘ ‘);
END LOOP;
fnd_file.put_line (fnd_file.LOG, ‘Inserted’);
END printelements;

Recent Comments