To load data from external sources into Oracle eBS you might consider using SQL*Loader to accomplish this. SQL*Loader is using comma seperated (csv) files with data and a so called control file (ctl). The control file tells the system how to import the csv file with data. The control file describes the table and columns to be loaded, what the seperator is of the incoming file etc. Next the SQL*Loader program exports a log file to give an overview of the process, a bad file of records that caused errors in the process, and a discard file for records that were not selected during the load.

Starting a SQL*Loader load can be done by command line by executing the below:
sqlldr db_user/db_password@host:port/sid control=control_file_name.ctl log=log_file_name.log
SQL*Loader can also be executed by starting a special concurrent program which you can create in Oracle E-Business Suite. Below the steps how to do this.
1) First of all you need to have a csv file with data – the csv can also contain header information. The header in a csv file can be skipped by adding a special parameter in the control file. Take note of the columns in the csv file.
2) You need a control file – for example see the below control file. There are a big number of commands you can use in the control file to completely have control on how data gets loaded into tables. If you want to know more than contact me on this topic.
SKIP = 1
LOAD DATA
INFILE ‘data_file_name.csv’
BADFILE ‘data_file_name.bad’
REPLACE INTO TABLE XXX.YOUR_CUSTOM_TABLE
FIELDS TERMINATED BY “,” OPTIONALLY ENCLOSED BY ‘”‘
TRAILING NULLCOLS
(
COLUMN1,COLUMN2,COLUMN3,…
)
SKIP=1
Tells SQL*Loader to exclude row 1 in the data file (to exclude the headers)
INFILE
Specifies the name of the incoming data csv file
BADFILE
Determines the bad file generated for any errors occured during the load
REPLACE
This command will first truncate the table and than add the records. If you change this in an APPEND command the records will be added only to the table specified without truncating first
FIELDS TERMINATED BY
Determines the seperator used in the data csv file
OPTIONALLY ENCLOSED BY
Determines an additional enclosing character like for example ” if you’re adding data which contains the column seperator used
TRAILING NULLCOLS
Is used to treat any missing data in the csv file as NULL for the table to be loaded
COLUMN1, COLUMN2, COLUMN3, …
Gives the column names to be loaded
3) Create the SQL*Loader Executable in Oracle E-Business Suite. Go to responsibility System Administrator – Concurrent – Program – Executable.
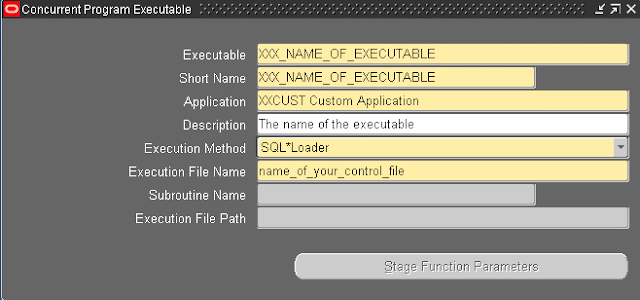
Give you executable a name, shortname and assign it to your customizations application. A description is optionally. Select Execution Method SQL*Loader to let eBS know SQL*Loader needs to be started. The Execution File Name holds the name of the control file you want to start (exclude the extension ctl here). The control file needs to be located in the bin directory of your customization application.
4) Create the concurrent program in Oracle E-Business Suite. Go to responsibility System Administrator – Concurrent – Program – Define.
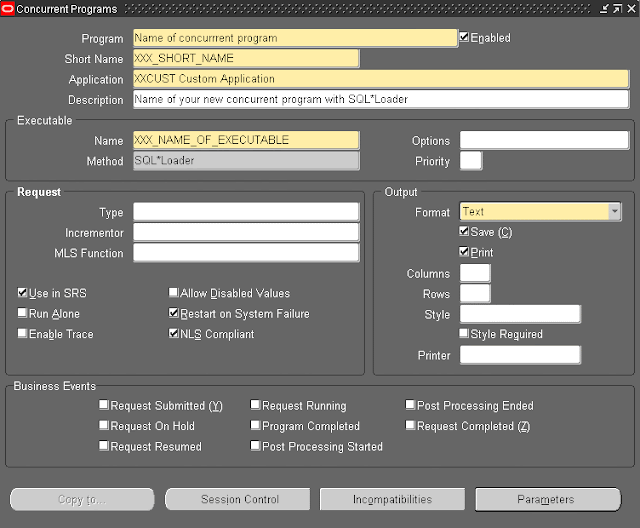
Give your concurrent program a name, a short name, assign it to your customization’s application and optionally provide a description. Assign your created executable to the concurrent program.
5) Add parameters to dynamically provide the incoming data csv file. Click on Parameters.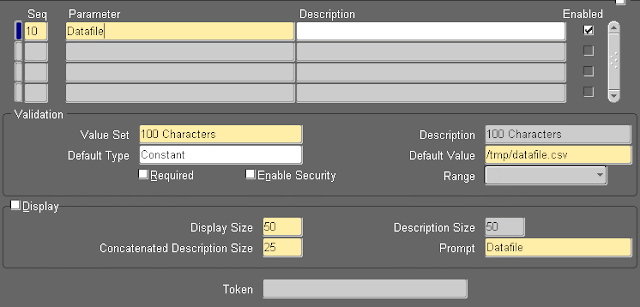
Add Sequence 10 and give the parameter a name. In this we want to provide a full path to the incoming data csv file so we use seeded Value Set 100 Characters to hold the path. Optionally add a default value.
6) When done creating the concurrent program add it to a Concurrent Request Group and start loading data in your tables.
Recent Comments