Here are the two rules you need to remember for table joins. Data from two (or more) tables can be joined, if the same column (under the same or a different name) appears in both tables, and the column is the primary key (or part of that key) in one of the tables. Having a common column in two tables implies a relationship between the two tables. The nature of that relationship is determined by which table uses the column as a primary key. This begs the question, what is a primary key? A primary key is a column in a table used for identifying the uniqueness of each row in a table. The table in which the column appears as a primary key is referred to as the parent table in this relationship (sometimes also called the master table), whereas the column that references the other table in the relationship is often called the child table (sometimes also called the detail table). The common column appearing in the child table is referred to as a foreign key.
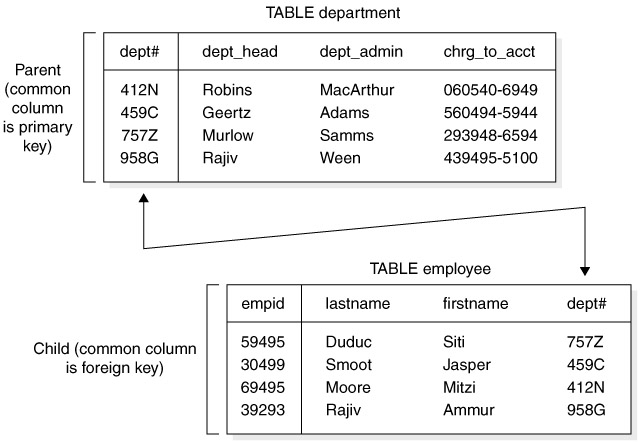
Let’s look at an example of a join statement using the Oracle traditional syntax, where we join the contents of the EMP and DEPT tables together to obtain a listing of all employees, along with the names of the departments they work for:
SQL> select e.ename, e.deptno, d.dname
2 from emp e, dept d
3 where e.deptno = d.deptno;
ENAME DEPTNO DNAME
———- ——— ————–
SMITH 20 RESEARCH
ALLEN 30 SALES
WARD 30 SALES
JONES 20 RESEARCH
Note the many important components in this table join. Listing two tables in the from clause clearly indicates that a table join is taking place. Note also that each table name is followed by a letter: E for EMP or D for DEPT. This demonstrates an interesting concept—just as columns can have aliases, so too can tables. The aliases serve an important purpose—they prevent Oracle from getting confused about which table to use when listing the data in the DEPTNO column. Remember, EMP and DEPT both have a column named DEPTNO
You can also avoid ambiguity in table joins by prefixing references to the columns with the table names, but this often requires extra coding. You can also give the column two different names, but then you might forget that the relationship exists between the two tables. It’s just better to use aliases! Notice something else, though. Neither the alias nor the full table name needs to be specified for columns appearing in only one table. Take a look at another example:
SQL> select ename, emp.deptno, dname
2 from emp, dept
3 where emp.deptno = dept.deptno;
How Many Comparisons Do You Need?
When using Oracle syntax for table joins, a query on data from more than two tables must contain the right number of equality operations to avoid a Cartesian product. To avoid confusion, use this simple rule: If the number of tables to be joined equals N, include at least N-1 equality conditions in the select statement so that each common column is referenced at least once. Similarly, if you are using the ANSI/ISO syntax for table joins, you need to use N-1 join tablename on join_condition clauses for every N tables being joined.
Cartesian Products
Notice also that our where clause includes a comparison on DEPTNO linking data in EMP to that of DEPT. Without this link, the output would have included all data from EMP and DEPT, jumbled together in a mess called a Cartesian product. Cartesian products are big, meaningless listings of output that are nearly never what you want. They are formed when you omit a join condition in your SQL statement, which causes Oracle to join all rows in the first table to all rows in the second table. Let’s look at a simple example in which we attempt to join two tables, each with three rows, using a select statement with no where clause, resulting in output with nine rows:
SQL> select a.col1, b.col_2
2 from example_1 a, example_2 b;
COL1 COL_2
——— ——————————
1 one
2 one
3 one
1 two
2 two
3 two
You must always remember to include join conditions in join queries to avoid Cartesian products. But take note of another important fact. Although we know that where clauses can contain comparison operations other than equality, to avoid Cartesian products, you must always use equality operations in a comparison joining data from two tables. If you want to use another comparison operation, you must first join the information using an equality comparison and then perform the other comparison somewhere else in the where clause. This is why table join operations are also sometimes referred to as equijoins. Take a look at the following example that shows proper construction of a table join, where the information being joined is compared further using a nonequality operation to eliminate the employees from accounting:
SQL> select ename, emp.deptno, dname
2 from emp, dept
3 where emp.deptno = dept.deptno
4 and dept.deptno > 10;
ANSI/ISO Join Syntax (Oracle9i and higher)
In Oracle9i, Oracle introduces strengthened support for ANSI/ISO join syntax. To join the contents of two tables together in a single result according to that syntax, we must include a join tablename on join_condition in our SQL statement. If we wanted to perform the same table join as before using this new syntax, our SQL statement would look like the following:
Select ename, emp.deptno, dname
from emp join dept
on emp.deptno = dept.deptno;
———- ——— ————–
SMITH 20 RESEARCH
ALLEN 30 SALES
WARD 30 SALES
JONES 20 RESEARCH
Note how different this is from Oracle syntax. First, ANSI/ISO syntax separates join comparisons from all other comparisons by using a special keyword, on, to indicate what the join comparison is. You can still include a where clause in your ANSI/ISO-compliant join query, the only difference is that the where clause will contain only those additional conditions you want to use for filtering your data. You also do not list all your tables being queried in one from clause. Instead, you use the join clause directly after the from clause to identify the table being joined.
Never combine Oracle’s join syntax with ANSI/ISO’s join syntax! Also, there are no performance differences between Oracle join syntax and ANSI/ISO join syntax.
Cartesian Products: An ANSI/ISO Perspective
In some cases, you might actually want to retrieve a Cartesian product, particularly in financial applications where you have a table of numbers that needs to be cross-multiplied with another table of numbers for statistical analysis purposes. ANSI/ISO makes a provision in its syntax for producing Cartesian products through the use of a cross-join. A cross-join is produced when you use the cross keyword in your ANSI/ISO-compliant join query. Recall from a previous example that we produced a Cartesian product by omitting the where clause when joining two sample tables, each containing three rows, to produce nine rows of output. We can produce this same result in ANSI/ISO SQL by using the cross keyword, as shown here in bold:
Select col1, col_2
from example_1 cross join example_2;
COL1 COL_2
——— ————-
1 one
2 one
3 one
1 two
2 two
3 two
1 three
Natural Joins
One additional type of join you need to know about for OCP is the natural join. A natural join is a join between two tables where Oracle joins the tables according to the column(s) in the two tables sharing the same name (naturally!). Natural joins are executed whenever the natural keyword is present. Let’s look at an example. Recall our use of the EMP and DEPT tables from our discussion above. Let’s take a quick look at the column listings for both tables:
SQL> describe emp
Name Null Type
————————– ——— ————
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
SQL> describe dept
Name Null Type
————————– ——— ————
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
As you can see, DEPTNO is the only column in common between these two tables, and appropriately enough, it has the same name in both tables. This combination of facts makes our join query of EMP and DEPT tables a perfect candidate for a natural join. Take a look and see:
Select ename, deptno, dname
from emp natural join dept;
ENAME DEPTNO DNAME
———- ——— ————–
SMITH 20 RESEARCH
ALLEN 30 SALES
WARD 30 SALES
Outer Joins
Outer joins extend the capacity of Oracle queries to include handling of situations where you want to see information from tables even when no corresponding records exist in the common column. The purpose of an outer join is to include non-matching rows, and the outer join returns these missing columns as NULL values.
Left Outer Join
A left outer join will return all the rows that an inner join returns plus one row for each of the other rows in the first table that did not have a match in the second table.
Suppose you want to find all employees and the projects they are currently responsible for. You want to see those employees that are not currently in charge of a project as well. The following query will return a list of all employees whose names are greater than ‘S’, along with their assigned project numbers.
SELECT EMPNO, LASTNAME, PROJNO
FROM CORPDATA.EMPLOYEE LEFT OUTER JOIN CORPDATA.PROJECT
ON EMPNO = RESPEMP
WHERE LASTNAME > ‘S’
The result of this query contains some employees that do not have a project number. They are listed in the query, but have the null value returned for their project number.
EMPNO LASTNAME PROJNO
000020 THOMPSON PL2100
000100 SPENSER OP2010
000170 YOSHIMURA –
000250 SMITH AD3112
In oracle we can specify(in Oracle 8i or prior vesrion this was the only option as they were not supporting the ANSI syntex) left outer join by putting a (+) sign on the right of the column which can have NULL data corresponding to non-NULL values in the column values from the other table.
example: select last_name, department_name
from employees e, departments d
where e.department_id(+) = d.department_id;
Right Outer Join
A right outer join will return all the rows that an inner join returns plus one row for each of the other rows in the second table that did not have a match in the first table. It is the same as a left outer join with the tables specified in the opposite order.
The query that was used as the left outer join example could be rewritten as a right outer join as follows:
SQL> — Earlier version of outer join
SQL> — select e.ename, e.deptno, d.dname
SQL> — from dept d, emp e
SQL> — where d.deptno = e.deptno (+);
SQL>
SQL> — ANSI/ISO version
SQL> select e.ename, e.deptno, d.dname
SQL> from emp e right outer join dept d
SQL> on d.deptno = e.deptno;
Full Outer Joins
Oracle9i and higher
Oracle9i also makes it possible for you to easily execute a full outer join, including all records from the tables that would have been displayed if you had used both the left outer join or right outer join clauses. Let’s take a look at an example:
SQL> select e.ename, e.deptno, d.dname
2 from emp e full outer join dept d
3 on d.deptno = e.deptno;

Recent Comments